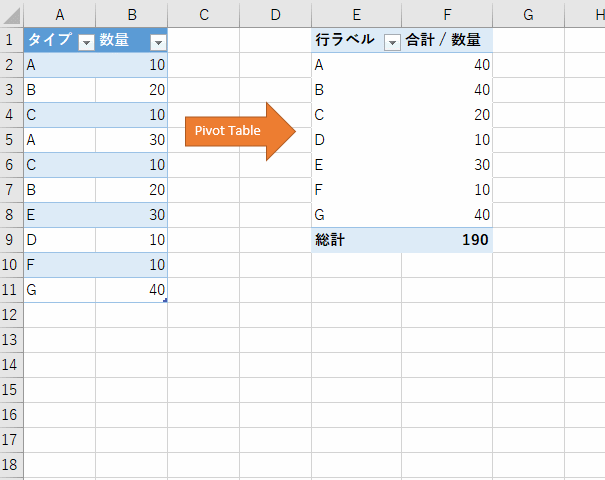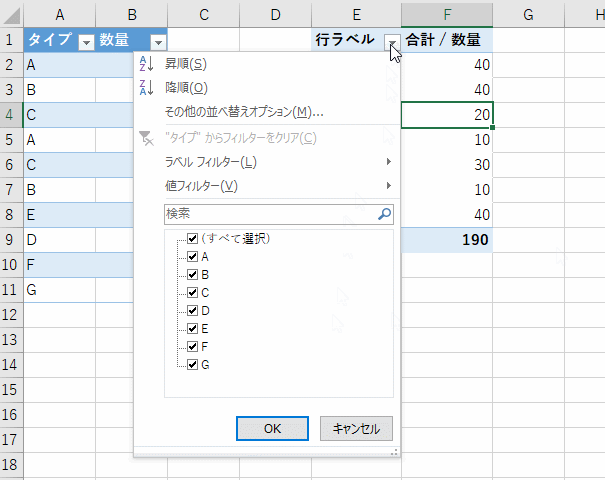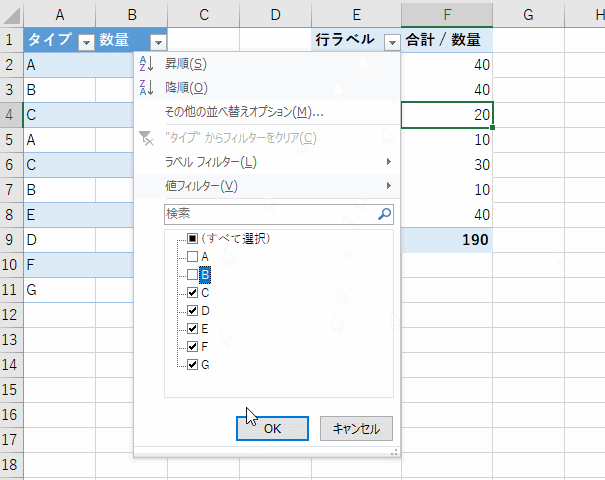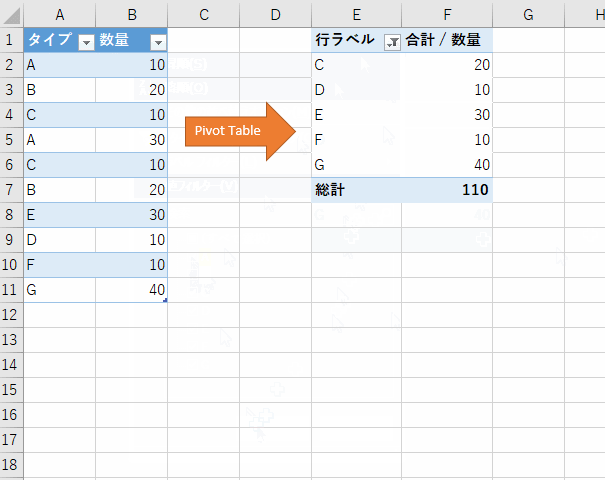
connpass や Doorkeeper の REST API を利用してIT勉強会のデータを取得して、Excel であれば JSON データを表形式のテーブルに展開し Pivot テーブルに取りこんで分析する、Power BI であれば、ファクトテーブルとして取りこんでレポート、ダッシュボード作成に利用する、などを過去のブログでも紹介しています。
その中で既に使っているやり方なんですが、意外にこの方法で悩んでいる方もいらっしゃるので、まとめて説明してみます。おおまかな手順は以下です。
1) APIを使ったデータ取得をパラメータを受け取って処理する関数にする
2) 渡したいパラメータ(for の 1 から n に相当)の要素をもったテーブルを作る
3) 要素をパラメータとして関数に渡し、結果をとる
4) エラーが発生している行を削除する
5) 関数の結果からピボットテーブルを利用する
ここから connpass の場合を例にとって説明します。Doorkeeper でも考え方は同じです。
1) APIを使ったデータ取得をパラメータを受け取って処理する関数にする
connpass の API の説明ページは以下で、そこでデータ取得のためのサンプルや、各種パラメータの説明があります。
connpass API リファレンス
https://connpass.com/api/v1/event/?keyword=JAWS のように keyward= に検索したいワードを入れることでレスポンスを JSON 形式で受け取ることができます。connpass の場合はレスポンスのデータ件数の初期値が10なので10件しか出力されないのですが、このcount パラメータは最大100に設定でき、かつ、初期値1の開始位置パラメータの start を設定することで 1-100、その次は 101-200、さらにその次は 201-300 と出力を受け取ることができます。URLは以下のようなものを生成できればいいわけです。
1-100件目を取得
https://connpass.com/api/v1/event/?keyword=JAWS&count=100&start=1
101-200件目を取得
https://connpass.com/api/v1/event/?keyword=JAWS&count=100&start=101
201-300件目を取得
https://connpass.com/api/v1/event/?keyword=JAWS&count=100&start=202
キーワードやcountは固定、start パラメータを上述のように変更してリクエストしすべての結果を貰って処理します。
以下は上述の 1-100件目を取得のURLを使って、connpass から JSON データを取得し、ワークシートにテーブルとして展開する手順です。VBAなどのコードを書かずにダイアログ設定だけで JSON をワークシートのテーブルとして展開できることがわかると思います。
[データ]タブの[データの取得と変換](これが Power Query) グループの [Webから] を選択して、URL の入力ボックスに上述のURLをコピーする。
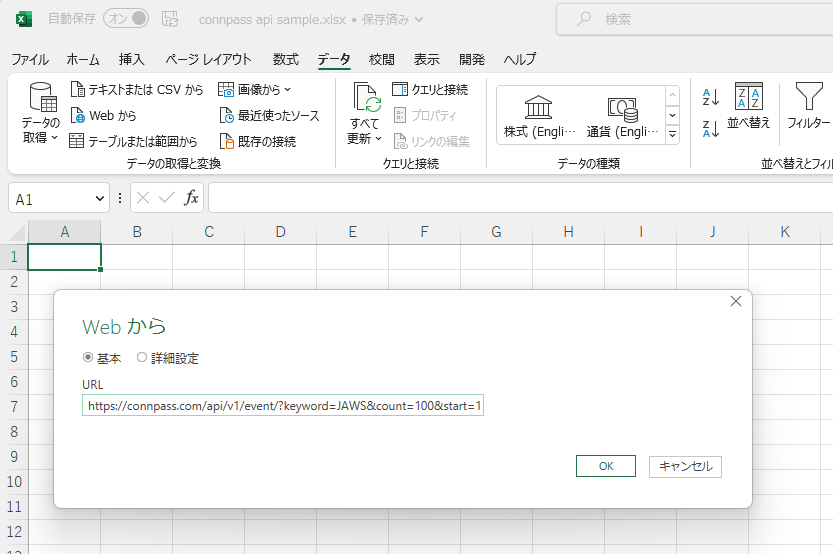
Power Queryエディタが立ち上がって、API リクエストの結果、受け取ったオブジェクトがアイコンで表示されるので、ここで右クリックメニューから [JSON] を選ぶ。

レスポンス情報の「まとめ」が表示される。ここでわかるのは 1番目から開始して、100件を返信として受け取って、可能な返信の件数は 1,135件ある、ということです。JSONで受け取った100件分は、events の List にはいっているので、[List] をクリックします。

Listが展開されて [Record] となりますが、この Record をクリックしてしまうと1件分だけが展開されます。これを全件展開してたいので、リボンの左はしにある [テーブルへの変換] をクリックします。

[テーブルへの変換] 確認のダイアログが表示されるので、そのまま [OK]

リスト形式のものが「テーブル形式」に変換されます。これによる赤丸の「展開」ボタンで、すべての行にある「レコード」が展開されます。


100件分がテーブルとして展開されます。


リボンの [閉じて読み込む] をクリックすると、Powery Query を閉じて、ワークシート上に JSON のレスポンス結果をテーブルに変換したデータが作成されます。

これが基本形です。
この URL の start に受け渡す部分をパラメータ化して変更できる「カスタム関数」を作成します。
いくつかのやり方があるようです。ここでは以下のように「詳細エディター」で Powery Query の M言語を直接いぢります。
Powery Query エディターが閉じられている状態なら、Excel のリボンの [データ] タブの [クエリと接続] グループの [クエリと接続] をクリックし、クエリと接続 ペインを表示して、先ほど作成したクエリをダブルクリックして Power Query エディターを起動します。

[ホーム]タブの [クエリ]グループの [詳細エディタ-] をクリックします。

(p1 as text) =>
そして、URLの部分の start= の直後をダブルコーテーションで閉じて、&p1 を追加します。
ソース = Json.Document(Web.Contents("https://connpass.com/api/v1/event/?keyword=JAWS&count=100&start="&p1)),
[完了]ボタンで詳細エディターを終了します。

これでこのクエリはパラメーター入力が必要なクエリ関数になりました。
名前もわかりやすいものに変えておきましょう。右側の[クエリの設定]ペインの名前プロパティで変更可能です。

2) 渡したいパラメータ(for の 1 から n に相当)の要素をもったテーブルを作る
この作成した関数を使って、1,101、201、301、、、、とパラメータを入力して、すべてのデータをひとつのテーブルすると Excel 上では分析するデータソースとして使いやすいです。ワークシートに展開すると 100万行の制限がありますが、Pivotテーブルで利用するデータソースとして使う場合は、必ずしもデータをワークシートに接続する必要はなく、接続情報として保存することで Pivot テーブルのソースとして使えます。
さて、APIでリクエストをして何件あるかはそのとき時でかわります。ただ、上記で API を投げたとき、少なくとも現時点では 1,135 件あることは分かっているので、1,101,201,,,で、1401 とか、1901 まであればカバーできそうなのはわかっています。
そこで 1, 101, 201, 301... 1901 のパラメータリストを作り、そこのデータをパラメータとして関数に渡して、それぞれ100件分のデータを取りこむ、という手順を Power Query を使って踏んでいます。
まず、[データ]タブの[データの取得と変換]グループにある[データの取得]から、空のクリエを選択します。

19個のパラメータを作成するので、入力ボックスに ={1..19} と入力します。すると、1から19までの数字がはいったリストが作成されます。

リボンのテーブルへ変換をして、リストフィールドの数値を使って 1, 101, 201 を作る数式を使った追加の列を作ります。数式は n*100-99 を使ってみます。
テーブル変換した後で、[列の追加]タブの[カスタム列]を選択します。新しい列名はパラメータ変数名の p1 にして、使用できる列 Column1 をダブルクリックすると カスタム列の式に代入されます。そこに *100-99 を追記して [OK] をクリックします。


パラメータはテキストを渡すので、p1列名の横の [ABC123] ボタンを押して、属性をテキストに変換します。

3) 要素をパラメータとして関数に渡し、結果をとる
4) エラーが発生している行を削除する
ここからがカスタム関数を作った醍醐味です。[列の追加]タブの[カスタム関数の呼び出し]をクリックして、ダイアログを開きます。列名はそのままで、関数クエリのドロップダウンでは作成したカスタム関数が表示されるので、それを選びます。

関数を選ぶと、その関数のパラメータに何をいれるかを指定できるドロップダウンリストがでます。列名として指定した p1 をパラメータとして渡す設定をします。

すると関数名の列が新しく追加されます。

11行以降がデータが無いためErrorになるので、この行を削除します。追加列を選択した状態で、[ホーム]タブの[行の削除]から[エラーの削除]を選択します。

削除が終わったら、列名の左にある展開ボタンをクリックして、100件分のデータの展開をします。列名が長くなるので、[元の列名をプレフィックスとして使用します]のチェックを外し、[OK]をクリックします。(以降のサンプルの図は Column1 を外していない図になります。すみません)

各列の属性を適切なものにします。特に集計をしたい列は[10進数]とする、日付の列は [日付/時刻/タイムゾーン]を選んでから、[日付]を選び、[列タイプの変更]ダイアログで [新規手順の追加] を選択して、Excel が理解できる形式に変更してください。


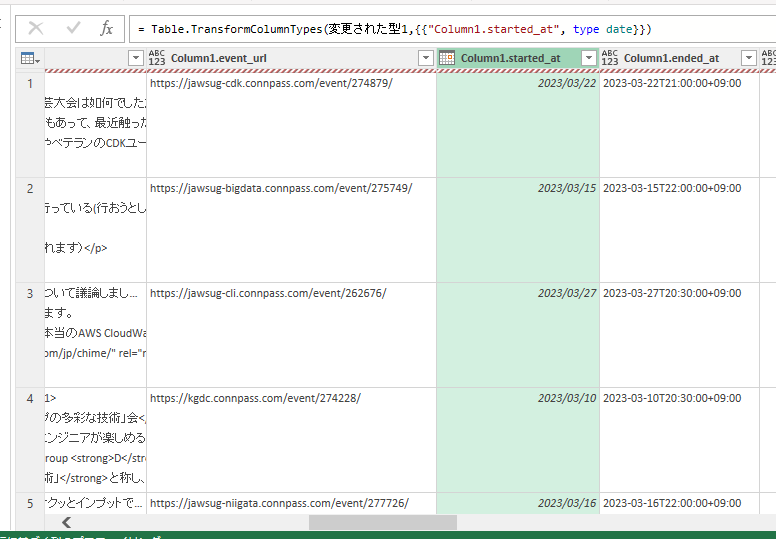
最後は不要な列を削除します。(必要な列だけ選んで他の列を削除するという操作)

[閉じて読み込む]をクリックすると、Power Queryエディタを閉じて、結果をワークシートに展開します。1136行(=データは1,135)で、最初に確認したAPIの返答の result_available の数と一致していることがわかります。

5) 関数の結果からピボットテーブルを利用する
ここまでくれば、あとは Pivotテーブルで集計できます。
すでにテーブル形式になっているので、[挿入]-[ピボットテーブル]で、この手順通りであれば [クエリ1]というテーブルが指定されている状態でピボットテーブルを作成します。
connpassの場合だと、started_at が開催日、accepted が申し込み人数で、Power Queryで日付データを Excel がわかる形式に変換しているので、以下のような Pivotテーブルが十数秒でできあがります。titleをカウントして何回の勉強会・イベントが開催されているかを集計しています。

この集計方法の最強にして最大の長所は「更新」できることです。一度、このピボットテーブルを作成してしまえば、[データ]タブの[すべて更新]をクリックすることで、再度 connpass に対して REST API を投げて、最新のデータを取得します。その間、Excel 下部のエリアに以下のような「バックグラウンド クエリを実行しています」メッセージが表示されます。

このメッセージが消えたら、ピボットテーブル上で右クリックメニューを表示して、そこから [更新] を選ぶことで、ピボットテーブルも最新になります。

注意すべき点
正確な集計にするためには keyword で取得した後のデータに「ゴミ」が混じっていないかのチェックを入念にしています。実際、この方法で取得したデータのテーブルはファクトテーブルであって、ある意味履歴のようなものです。対象とすべきデータなのかどうかのチェックはスタースキーマであればディメンジョンテーブル(マスターテーブル)と付き合わせるので、ピボットテーブル分析にいく手前で別のステップを踏んで、分析用のデータソーステーブルを作成します。[中止] などの言葉がタイトルにあれば省く、などの例外処理も気がついたら入れていくので、クエリは一度作ったら終わりではなく、常にデータの信頼性を担保するためのチェックをします。このケースの場合は、厳格な命名規則が適用されているわけではないので、毎週、毎月のように新規に追加されたデータから、クエリが正しいかを確認する作業をしています。
一方で、ゴミの有無だけではなく、データの取りこぼしが発生することも確認しています。理由ははっきりとわかっていませんが、一度取りこぼしたデータは次回の更新時にとってくることはないため、一次的なものというより keyword クエリにかからない connpass 側のデータの持ち方かと思います。この場合は強制的に event_id を指定すると詳細を取りこむことができるので、対象となるURL/event_idで強制取り込みリストを作り、そこを参照させて個別にデータを取りこむようにする工夫をしています。
過去の投稿と被っているところも多々ありますが、何かしらの参考になれば幸いです。